3 章 レスポンスデータの設計
3.1 データフォーマット
- JSON にデフォルトとして対応し、需要や必要性に応じて XML 等に対応する
- データフォーマットの指定方法の実装
- クエリパラメータ (
https://api.example.com/v1/users?format=xml) - 拡張子 (
https://api.example.com/v1/users.json) - リクエストヘッダのメディアタイプを指定 (
Accept: application/json)
- クエリパラメータ (
- 基本的にはクエリパラメータで実装する
3.2 JSONP の取り扱い
JSONP (JSON with padding)
クロスサイト環境でほかのオリジンから JSON データを取得するために考案された仕組み。XHTTPRequest は同一生成元ポリシーの制限によって、同じドメインへのアクセスしか行うことができない。
script タグでは src 属性に他ドメインを指定できることを利用する。
- ドメイン A でコールバック関数を用意
- script タグを生成しドメイン B にアクセス。この時 url パラメータでコールバック関数の名称を伝える。(
<script src="http://domain_b/?callback=callback"></script>) - ドメイン B ではデータ取得等を行い、データを引数としたコールバック関数を返却する。(
callback({"id": 123, "name": "saeed"})) - ドメイン A は B から返却されたコールバック関数を実行する
コールバック関数の名前はクエリパラメータ (callback) で指定できるようにするのが一般的。
コールバック関数を動的に生成する場合等に、別々のコールバック関数を用意することができるようになるため。
callback パラメータが指定されている場合に JSONP を要求していると判断する。
script 要素はエラーステータスコード (400 等) が返るとスクリプトの読み込みを停止するため、JSONP に対応した場合にエラーコードを返すようにするとクライアント側ではそのエラーを検知できない。
=> エラーが発生しても 200 を返す。レスポンスボディ内にエラー情報を入れ込む。
3.3 データの内部構造の考え方
まず考えるべきは、API のアクセス回数がなるべく減るようにすること。ユースケースを考える必要がある。
(ユーザー一覧の結果で ID だけ返す => 利用する側はユーザー情報も欲しいはず => 一緒にユーザー情報も返したほうが利用しやすい)
3.3.1 レスポンスの内容をユーザーが選べるようにする
多数の外部ユーザーが利用するような API はすべてユースケースを想定することはできない。
シンプルな解決法はできる限り多くのデータを返す。
ただこの方法ではデータ量が必要以上に大きくなりすぎる。
⇒ クエリパラメータで取得したい項目をユーザー側が自由に選択できるようにする
(http://api.example.com/v1/users/123?fields=name,age)
3.3.2 エンベロープは必要か
エンベロープ
上記のように返却するデータに共通したメタデータを含んだ構造のことをエンベロープと呼ぶ。
冗長な表現のため基本期にはやるべきではない。
HTTP のレスポンスヘッダで同様のことができる。むしろ HTTP の知識さえあればメタ情報やエラー情報の意味を理解しやすいため、ユーザーフレンドリーになる。
ただしJSONPでは利用したほうが便利になる。
3.3.3 データはフラットにすべきか
返却するデータを階層的に表すか、フラットに形で表すかは状況次第。
階層
{
"id": 123,
"sender": {
"id": 456,
"name": "Taro Ymamoto"
},
"receiver": {
"id": 789,
"name": "Kenji Kato"
}
}
フラット
{
"id": 123,
"sender_id": 456,
"sender_name": "Taro Yamamot",
"receiver_id": 789,
"receiver_name": "Kenji Kato"
}
上記の例では sender と receiver は同じユーザーという構造を表すため階層構造で表現したほうが、利用者側はユーザー型として扱いやすくなる。
{
"id": 123,
"name": "Tanaka Taro",
"profile": {
"birthday": "193848754",
"gender": "male",
"languages": ["ja", "en"]
}
}
上記の profile 項目のように単にまとめるだけの階層構造はあまり意味がない。フラットに表現したほうがデータサイズが小さくなる。また profile 単体で処理を行うことは考えにくいため、前出のユーザーの場合のように利用者側の利便性もよくならない。
3.3.4 配列とフォーマット
友人一覧等の配列で値を返す場合、以下の理由からそのまま配列を返すよりもレスポンス全体をオブジェクトにして返すほうが良い。
- レスポンスデータが何を指しているかわかりやすい
- レスポンスデータをオブジェクトに統一できる (クライアント側で共通の前処理が容易になる)
- セキュリティ上のリスクを避けることができる
トップレベルが配列である JSON は「JSONインジェクション」という脆弱性に対するリスクがあるため、基本的には API のレスポンスとしてオブジェクトを返すようにするべき。
3.3.5 配列の件数、あるいは続きがあるかをどう返すべきか
全体の件数を把握したうえで現在取得済の件数を考えれば続きがあるかはわかる。
ただし、全体の件数を取得する処理はコストが大きいことが多いので、実際に取得するどうかはユースケースを考える必要がある。
全体の件数が必要ないなら、サーバー側では取得件数 +1 件の取得を試みて、実際に取得件数 +1 件取得できれば、続きがあるとして考えることができる。
続きがあることの返し方は 2 つ
- 「hasNext」といった名前で結果に含める
- 次のデータ取得に必要な「パラメータ」や「URL」を結果に含める
3.4 各データのフォーマット
3.4.1 各データの名前
データ項目の名前についての考え方
- 多くの API で同じ意味に利用されている一般的な単語を用いる
- なるべく少ない単語数で表現する
(エンドポイント名が/users なら userId ではなく id で良いなど、エンドポイント名も考慮に入れる必要あり) - 複数の単語を連結する場合、連結方法は API 全体を通して統一する
- 省略系は極力利用しない
- 単数形/複数形に気を付ける
(この項目で返る値が複数になる可能性があるのか、1つのみなのか)
3.4.2 性別のデータをどう表すか
項目名によって変わる。
sex (生物学的な性別)
生物学的な性別はその他 (不明等) を含めても 3 種類
⇒文字列 (male, female 等) や数字 (1: male, 2: female)
gender (社会的・文化的性別)
社会的に認められつつある性別 (Cis Woman, Trans 等) も含まれるため数が多い。
また今後増減する可能性がある。
⇒基本的に文字列で表す
どちらの項目名を使うかは、サービスが生物学的な性別が必要な場合は sex、そうでない場合は gender を利用する。
API 全体で統一すべき。
3.4.3 日付のフォーマット
フォーマット例
| 形式名 | 例 |
|---|---|
| RFC 822 | Sun, 06 Nov 1994 08:49:37 GMT |
| RFC 850 | Sunday, 06-Nov-94 08:49:37 GMT |
| ANSI C の astime() 形式 | Sun Nov 6 08:49:37 1994 |
| RFC 3339 | 2015-10-12T11:30:22+09:00 |
| Unix タイムスタンプ (epoch 秒) | 1396821893 |
広く一般に公開され、どのようなユーザーが利用するのか予測が難しい API(LSUDs をターゲットとした API) ではRFC 3339を利用するのがよい。
タイムゾーンはUTC(協定世界時, +00:00) を利用するのがよい。
自社アプリ等で SSKDs 対象の場合は Unix タイムスタンプも候補に挙がる。
3.4.4 大きな整数と JSON
大きな数字は処理するシステムや言語によってはトラブルになることがある。
例として JavaScript では数値をすべて 64 ビット浮動小数として扱うため、下記を実行すると 462781738297483260 となり誤差が生じる。
このような問題を回避するためには、ID などで巨大な数値を扱う場合は数値をそのままかえすのではなく、文字列として返すと回避することができる。(Twitter API では数値とともに文字列を格納して返している)
3.5 レスポンスデータの設計
- API は内部で持っている DB 等のデータ構造をそのまま反映する必要はない
- ユーザー情報を一つのオブジェクトとして定義すると、API 通して共通して利用することで、ユーザー側は同じロジックで処理ができる
- クライアント側の利用しやすい形に、かつシンプルにする
- 結局、API のユースケースを考えて設計する必要がある
3.6 エラーの表現
クライアント側がエラーの原因の調査・特定に役立つ情報をなるべく多く返す必要がある。
3.6.1 ステータスコードでエラーを表現する
| ステータスコード | 意味 |
|---|---|
| 100 番台 | 情報 |
| 200 番台 | 成功 |
| 300 番台 | リダイレクト |
| 400 番台 | クライアントサイドに起因するエラー |
| 500 番台 | サーバーサイドに起因するエラー |
データとしてエラー情報を返すが、HTTP レスポンスのステータスコードとして 200 番台を返すようなことはしてはならない。
適切なステータスコードで返すことで、クライアント側の原因特定につながる。
ピッタリくるステータスコードが存在しない場合は、"200", "400" 等の 00 番を利用する。
3.6.2 エラーの詳細をクライアントに返す
ステータスコードは汎用的な意味を表す。→エラーの詳細情報も返す必要がある。
エラーの内容を返す方法は大きく 2 つ。
- レスポンスヘッダに入れる
("X-MYNAME-ERROR-MESSAGE: Bad authentication token" のように独自のヘッダ項目を利用する) - レスポンスボディに入れる
ほとんどの API はレスポンスボディにエラー情報を入れて返している。
→クライアント側の利便性がよいためか
3.6.3 エラー詳細情報には何を入れるべきか
返す内容は以下の通り。
- エラーの詳細コード
- エラーメッセージ (人間が読める形式)
- さらなる情報が記載されたドキュメントページの URI
エラーの詳細情報は API ごとに決める。既存のステータスコードと区別できるようにする。4 桁数字でステータスコードと同様に番台でカテゴリ分けするとよい。
エラーメッセージエンドユーザーに直接表示できるような「非開発者向けメッセージ」と開発者が原因特定に利用できるような「開発者向けメッセージ」を両方含める方法もある。
3.6.4 エラーの際に HTML が返ることを防ぐ
基本的に API の結果は JSON や XML で返ることを期待される。
nginx 等のサーバーやアプリケーションフレームワークでデフォルトで 404 エラー等が HTML で返ることになっていることが多い。
エラー発生時でも適切なフォーマットでデータが返るようにする。
3.6.5 メンテナンスとステータスコード
API を停止しなければならない自体は極力避けるべき。API を利用しているサービスが動作しない、または一部動作が制限されるため。
メンテナンスで停止する場合は 503(HTTP 503 Service Unavailable)を返す。
予定されたメンテナンスで終了予定時刻が分かっている場合はそれも通知するべき。
Retry-Afterという HTTP ヘッダにいつメンテナンスが終わるかを具体的な日付や、現在時刻からアクセス可能になるまでの秒数を入れる。
3.6.6 意図的に不正確な情報を返したい場合
セキュリティ上やその他の理由で情報を曖昧にしたいケースが存在する。
ブロック機能がある場合に、ブロックされたユーザーがブロックしたユーザー情報を取得しようとした場合等。エラーで返すが、メッセージでブロックされていると伝えるとさらなるトラブルにつながる可能性がある。
→「ブロックされた側からみるとブロックした側はすでに存在しないと同義」として 404 を返すことも可能。
ログイン時に「メールアドレスが存在しない」「パスワードが違う」等の原因を伝えるのは悪意を持ったユーザーに対しても情報を与えることになる。
正確な情報を返すのはあくまでも開発の効率化やユーザー体験の向上のため。
正確な情報を返すことでそれらが阻害されるならば返すべきではない。
4 章 HTTP の仕様を最大限利用する
4.1 HTTP の仕様を利用する意義
標準の仕様をできる限り利用した API は第 3 者にとっても理解しやすい。
利用時のバグ混入を減らしたり、再利用可能性が高くなる。
4.2 ステータスコードを正しく使う
ステータスコードは HTTP のレスポンスヘッダの先頭に必ず入っている 3 桁の数字。リクエストがサーバによって処理された際のステータスを表す。
汎用的な HTTP のクライアントライブラリは基本的にステータスコードをみて振る舞いを決めるため、適切なステータスコードを返さないと余計な問題を引き起こすことになる。
4.2.1 200 番台: 成功
指定したデータの取得、あるいはリクエストした処理が成功した場合には 200 番台のステータスコードを返す。
- 201 Created (POST リクエストメソッド)
- 202 Accepted (非同期処理: リクエスト受領かつ処理の未完了)
- 204 No Content (レスポンス空: DELETE で削除を行った場合等)
DELETE 時には基本的にはデータを返さない。PUT/PATCH, POST の場合はデータを返す。
4.2.2 300 番台: 追加で処理が必要
リダイレクト等で使用される。
リダイレクトの場合はLocationというレスポンスヘッダにリダイレクト先の新しい URI が含まれる。
ウェブサイトのように URI の変更にともなってリダイレクトを行うのは好ましくない。
クライアント側でリダイレクトにたいして実装をしているかわからないため。
何らかの理由でリソースが別の URI に変わる等でリダイレクト行う可能性がある場合は、必ずドキュメントに記載を行う。
- 300 Multiple Choices (指定 URI が取得するデータを一意に特定するには曖昧な場合)
- 304 Not Modified (前回のデータ取得から更新されていない。レスポンスボディは空)
4.2.3 400 番台: クライアントのリクエストに問題があった場合
サーバー側には問題はないが、クライアントが送ってきたリクエストが理解できなかったり、実行が許可されていない場合には 400 番台のステータスコードを返す。
- 400 Bad Request (ほかの 400 番台ステータスコードに当てはまらない場合)
- 401 Authentication (認証エラー: アクセス元が識別できない)
- 403 Authorization (認可エラー: 操作が許可されていない)
- 404 Not Found (アクセスしようとしたデータが存在しない)
(指定したデータが存在しないのか、URI が存在しないのか詳しい情報の返却が必要) - 405 Method Not Allowed (エンドポイントは存在するがメソッドが許可されていない)
- 406 Not Acceptable (クライアント指定のデータ形式に API が対応していない)
- 408 Request Timeout (タイムアウト)
- 409 Conflict (リソース競合: 同じ ID でユーザー登録を使用とする等)
- 410 Gone (アクセスしたデータかつて存在したが、現在は存在しない場合。404 との違いはデータがかつて存在していたかどうか)
- 413 Request Entity Too Large (リクエストボディが大きすぎる)
- 414 Request-URI Too Long (リクエストヘッダが大きすぎる)
- 415 Unsupported Media Type (リクエストヘッダの Content-Type で指定されているデータ形式にサーバー側が対応していない場合 (リクエストボディのデータ形式))
- 429 Too Many Requests (アクセス回数が許容範囲の限界を超えた場合)
4.2.4 500 番台: サーバに問題があった場合
サーバー側に問題があった場合は 500 番台のエラーを返す。
- 500 Internal Server Error (サーバー側でエラーが発生して処理が停止した)
- 503 Service Unavailable (サーバーが一時的に利用できない (意図的がそうでないかは問わない))
500 番台のエラーはログを監視し、管理者に通知が行くように設定、再発防止を図る。
4.3 キャッシュと HTTP の仕様
キャッシュのメリットは以下の通り
- ネットワークが切れた場合でもある程度サービスを継続できる
- サーバへの通信回数・転送量が減る
(ユーザーの体感速度向上やユーザー/サーバ側のコスト低減につながる)
プロキシサーバーがある場合はデータ鮮度に気を付ける必要あり。
4.3.1 Expiration Model (期限切れモデル)
レスポンスデータにキャッシュの保存期間を設定しておき、期限が切れたら再度アクセスをしてデータ取得を行う。
保存期間の指定方法は以下の 2 つ。
Cache-Control レスポンスヘッダを利用
現在時刻からの秒数を指定を行う。
max-age の計算には Date ヘッダ (レスポンスが生成されたサーバ側の日時) が利用される。
Expires レスポンスヘッダを利用
期限切れを絶対時間で RFC1123 で定義された形式で指定する。
両方を併用した場合はCache-Control が優先される。
4.3.2 Validation Model (検証モデル)
保持しているキャッシュが有効かどうかをサーバに問い合わせる方法 (条件付きリクエスト)。
問い合わせの結果として、有効の場合は「有効である」という情報のみ、有効でない場合は最新のデータを返す。
通信によるオーバーヘッドは変わらないが、転送データが軽減できる。
条件付きリクエストでは「保持してるデータの状態」として最終更新日時やエンティティタグ(MD ハッシュ等) をサーバに伝える。
これらはサーバ側で生成され、クライアント側でキャッシュとして保存される。
最終更新日時とエンティティタグのやり取りは以下のヘッダが利用される。
レスポンスヘッダ
それぞれLast-Modified とETag が利用される。
リクエストヘッダ
それぞれIf-Modified-SinceとIf-None-Matchヘッダを利用する。
サーバー側からのレスポンスではステータスコードはキャッシュが有効な場合は304で空ボディ、変更があった場合は200とともに最新データを返す。
4.3.3 Heuristic Expiration(発見的期限切れ)
サーバの更新頻度や状況を参考に、クライアント側でキャッシュの有効期限を決める方法を Heuristic Expiration(発見的期限切れ)とよぶ。
4.3.4 キャッシュさせたくない場合
Cache-Control ヘッダを以下のように利用してキャッシュをさせたくないことをクライアント側に伝えることができる。
4.3.5 Vary でキャッシュの単位を指定する
キャッシュを行う際に、URI 以外にどのリクエストヘッダ項目をデータを一意に特定するのに利用するかを指定する場合はVary ヘッダを利用する。
(Accept-Language ヘッダに指定の言語によってレスポンスの利用言語を変える場合等に利用される[サーバ駆動型コンテンツネゴシエーション\の一例])
4.3.6 Cache-Control ヘッダ

stale-while-revalidate
stale-while-revalidate=600 のように秒数を指定する。レスポンスヘッダに指定する。
プロキシサーバーが max-age で指定された秒数を超えた後に、キャッシュを返しつつ非同期でキャッシュの検証を行う時間を指定できる。
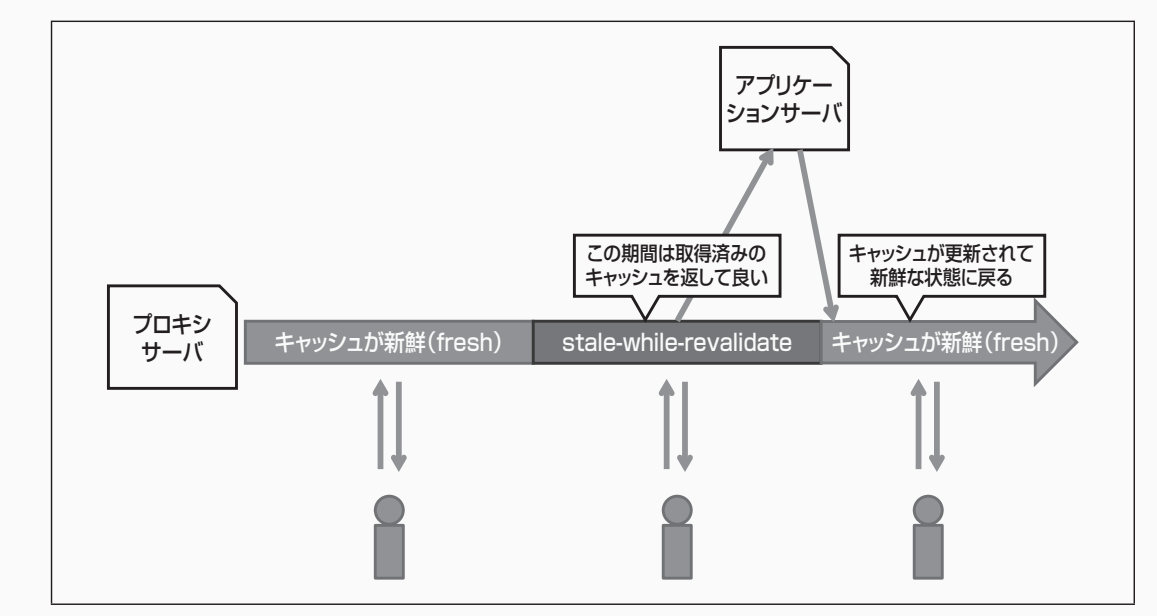
stale-if-error
オリジンサーバへのアクセスが何らかの理由で失敗した時に、保持している新鮮でないキャッシュをクライアントに返してもよい秒数を指定する。
サーバの停止等があっても少しの間サービスを継続することができる。
4.4 メディアタイプの指定
HTTP のリクエスト、レスポンスにおいて送信するデータ本体の形式を指定するのにメディアタイプが利用される。
メディアタイプの記述方法は以下の通り。
トップレベルタイプ名 / サブタイプ名 [ ; パラメータ]
トップレベルタイプ名はデータ形式が大別してテキストなのか画像なのか等のカテゴリを示し、サブタイプ名が具体的なデータ形式を示す。
| メディアタイプ | データ形式 |
|---|---|
| text/plain | プレーンテキスト |
| text/html | HTML 文書 |
| application/rss+xml | RSS フィード |
| image/jpeg | JPEG 画像 |
| image/svg+xml | SVG 画像 |
基本的には text/css、text/html を除き、テキストデータとして開くことが可能でも、トップレベルタイプ名は application を利用することが多い。
4.4.1 メディアタイプを Content-Type で指定する必要性
全ての API は適切なメディアタイプをクライアントに返すべき。クライアントの多くは Content-Type の値を使ってデータ形式を判断しているため。
4.4.2 x- で始まるメディアタイプ
application/x-msgpack のようにサブタイプが x- で始まるものは、このメディアタイプが IANA(Internet Assigned Numbers Authority) に登録されていないことを示す。
例外的に HTML のフォームデータを送信する際に使われる application/x-www-form-urlencoded だけは RFC1866 で明記され、IANA に登録された正式メディアタイプになっている。
4.4.3 自分でメディアタイプを定義する場合
RFC6838 において x- で始まるメディアタイプが未登録のメディアタイプを表すものとはみなされないと明記されているため、独自メディアタイプとして x- で始まるものを定義するべきではない。
サブタイプをその登録方法によって分類するためのカテゴリである
Registration tree を利用するべき。サブタイプの先頭に接頭辞を付けて区分する。
| ツリー名 | 接頭辞 | 説明 |
|---|---|---|
| Standards tree (標準ツリー) | なし | IANA に登録されている一般的なデータ形式 |
| Vendor tree (ベンダツリー) | vnd . | 広く利用されることを目的としているものの、特定の企業や団体が管理しているデータ形式 (Excel 等) |
| Personal tree (パーソナルツリー) | prs. | 実験的な実装、あるいは公に公開されることのない製品においてのみ扱うデータ形式 |
| Unregistered tree (未登録ツリー) | x. | ローカル環境等のプライベート環境のみで利用するデータ形式。ベンダツリーやパーソナルツリーで十分なため基本的には利用は推奨されていない。 |
公開 API において独自のメディアタイプを定義する場合は、基本的にはベンダツリーを利用する。フォーマットは以下の通り。
application/vnd.companyname.awesomeformat
4.4.4 JSON や XML を用いた新しいデータ形式を定義する場合
JSON や XML などの標準化されたデータ形式を使って、独自のデータ形式を定義する場合は +xml や +json のように用いたデータ形式を + に続けて記述する。
| メディアタイプ | データ形式 |
|---|---|
| application/rss+xml | RSS フィード |
| application/atom+xml | Atom フィード |
4.4.5 メディアタイプとセキュリティ
正しいメディアタイプを指定していない場合、ブラウザを介した場合にセキュリティ上の問題を引き起こす可能性がある。
JSON ファイルを間違って text/html で配信してしまった場合、その JSON ファイルの URI を直接叩いてアクセスした際に、ブラウザはデータ形式をもとに HTML として表示する。
この時 JSON 中に javascript が埋め込まれていた場合にそれが実行されてしまう。
4.4.6 リクエストデータとメディアタイプ
Accept ヘッダ
クライアントが「どのメディアタイプが受け入れ可能か」をサーバに伝えるために使われる。複数のメディアタイプを列挙でき、q(Quality Value) で優先度を指定できる。
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, image/webp;1=0.8
クライアント側が欲しいデータ形式をサーバ側に伝える方法として Accept ヘッダは利用されるが、URI のクエリパラメータで指定する方法も一般的で手軽である。どちらを利用するかは議論が分かれる。
4.5 同一生成元ポリシーとクロスオリジンリソース共有
XHTTPRequest では異なるドメインに対してアクセスを行い、レスポンスデータを読み込むことができない。これは同一生成元ポリシー(Same Origin Policy) というセキュリティ上のポリシーによるもの。
異なる生成元にアクセスしたい場合は、クロスオリジンリソース共有 (CORS: Cross-Origin Resource Sharing) を利用する。
4.5.1 CORS の基本的なやりとり
http://www.example.com/ から http://api.example.com/ にアクセスする場合。
- クライアント側から
Originヘッダで生成元 (http://www.example.com/) を指定する。 - サーバ側では許可する生成元一覧を保持し、Origin ヘッダの生成元が一覧に存在するかチェックを行う。
- 存在しない: 403 エラーを返す
Access-Control-Allow-Originというレスポンスヘッダに Origin ヘッダと同じ生成元を入れてレスポンスを返す。
4.5.2 プリフライトリクエスト
プリフライトリクエストは実際に生成元をまたいだリクエストを行う前に、そのリクエストが受け入れられるかどうかをチェックを行うこと。行う必要があるのは以下の場合。
- HTTP メソッドが Simple Methods (HEAD/GET/POST) 以外の場合
- 以下のヘッダ以外を送信しようとしている
- Accept
- Accept-Language
- Content-Language
- Content-Type
- 以下のメディアタイプ以外を指定している
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
プリフライトリクエストは OPTIONメソッド を利用して送信される。
プリフライトリクエストは通常はブラウザが自動的に発行するため、開発者が自分でリクエストを作成する必要はない。
4.5.3 CORS とユーザー認証情報
CROS ではユーザー認証情報 (Credential) を送信する場合は追加の HTTP ヘッダを利用する必要がある。
- クライアント側
CookieヘッダやAuthenticationヘッダに認証情報を埋め込むwithCredentialsプロパティに true をセットする
- サーバ側
Access-Control-Allow-Credentialsヘッダに true を入れて返す
4.6 独自の HTTP ヘッダを定義する
適切なヘッダが存在しないメタデータを送りたい場合は、独自の HTTP ヘッダを定義することができる。新しく定義する場合は、x- という接頭辞を付けて、次にサービスや組織等の名称を付けるのが一般的。
(例: x-GitHub-Request-Id)
5 章 設計変更しやすい Web API を作る
5.1 設計変更のしやすさの重要性
API は何らかのアプリケーションのインターフェースとしての役割を持つ。
アプリケーションは機能の追加やバグの修正等で常に変化するため、API の変更は避けることができない。
5.1.1 外部に公開している API の場合
LSUDs の場合。
大きな仕様変更は API を利用している外部ユーザーやサービスに大きな影響を与える。
結果として API の利用をやめる可能性がある。
5.1.2 モバイルアプリケーション向け API の場合
SSKDs の場合。
外部に公開している場合に比べれば、利用しているのは自分が公開したモバイルアプリケーションのみなので影響は少ない。
ただし、モバイルアプリケーションのアップデートはユーザーが自分でアップデートをする必要がある場合がほとんど。そのため API の変更内容によっては古いクライアントを利用しているユーザーが使えなくなる可能性がある。
5.1.3 ウェブサービス上で使っている API の場合
API の変更もクライアント側の変更も自分たちのタイミングで実施ができるため、上 2 つに比べれば影響は少ない。
ブラウザキャッシュの問題は残る。
Note
一度公開した Web API の仕様変更はいずれにせよ何らかの問題が発生する危険性がある。
5.2 API をバージョンで管理する
問題回避の最も良い方法は、一度公開した API をできる限り変更しないこと。
新しいエンドポイントや別のパラメータを付けた URI など、何らかの新しいアクセス形式で公開を行う。
=> 古いクライアントは旧 API を利用し、新しいクライアントは新 API を利用できる。
新旧の API を共存させる方法として API に何らかの形式でバージョン番号を振っていく。
5.2.1 URI のバージョンを埋め込む
| サービス | エンドポイント |
|---|---|
| Twitter(旧バージョン 1) | http://twitter.com/statuses/user_timeline.xml |
| Twitter(新バージョン 1) | https://api.twitter.com/1/statuses/user_timeline.json |
| Twitter(バージョン 1.1) | https://api.twitter.com/1.1/statuses/user_timeline.json |
URI のパスの一番先頭にバージョン番号を埋め込む。v1 のようにバージョン番号であることを示す v を付けることもある。
5.2.2 バージョン番号をどう付けるか
基本的は API のバージョンは簡単に上げるべきではないため、整数でカウントアップしていく。
セマンティックバージョニングとは異なる。
小さな変更は後方互換性を担保して対応し、後方互換性を失うほど大きく重要な変更を行う場合のみバージョンを上げる。
5.2.3 バージョンをクエリ文字列に入れる
http://api-public.netflix.com/catalog/titles/series/703?v=1.5
パスに埋め込む場合と異なり、クエリ文字列の時は省略が可能。省略した場合はデフォルト(最新版が多い)のバージョンが利用される。
指定を省略しているユーザーがバージョンアップの際に自動的に最新版 API を利用することになり、問題が発生する可能性がある。
5.2.4 メディアタイプでバージョンを指定する方法
- クライアント側
- バージョン番号を含むメディアタイプを指定する
Accept: application/vnd.exmple.v2+json
- サーバー側
- サーバー側はレスポンスの際に
Content-Type, Varyヘッダを付ける - メディアタイプによってレスポンスが変わるのでキャッシュの際に
Acceptヘッダの考慮が必要 Content-Type: application/vnd.example.v2+json
Vary: Accept
- サーバー側はレスポンスの際に
クライアント側のライブラリによっては独自メディアタイプは正常に認識していもらえない可能性がある。
→独自の HTTP ヘッダを定義して、そのヘッダを用いてバージョン指定する方法もある。
5.2.5 どの方法を採用するべきか
どの方法も一長一短。
URI パスにバージョンを含める方法が最も広く利用されている。
5.3 バージョンを変える際の指針
後方互換性を保つことが可能な変更は、可能な限り同じバージョンでのマイナーバージョンアップで対応し、どうしても後方互換性を保ったまま修正を行うことが難しい場合のみ にバージョンを上げるべき。
データ名の変更や形式の変更等ではバージョンは上げない。ドキュメント等に古いやり方はバージョンアップの際に廃止される旨を記載し、古い項目の利用時に注意できるようにする。
後方互換性を保たなくてよい変更の例
- セキュリティや権限などのルールを変更した場合
(認証を追加する・ベーシック認証を廃止し OAuth のみに変更する等) - 開発初期の API 等のルール未整理のまま拡大した API の整理等
5.3.1 常に最新版を返すエイリアスは必要か
基本的には不要。同じ方法でのアクセスで挙動が変化する可能性があるのは、利用者側からしてみれば利用しづらい。
5.4 API の提供を終了する
API を終了する場合、特に広く一般に公開された API の提供を終了する場合には、事前に終了日時をアナウンスし、利用者にそれまでに対応するように周知徹底をする。
5.4.1 ケーススタディ: Twitter の場合
バージョン 1.0 の廃止、1.1 への移行
Blackout Test
一時的に終了する API を停止してアクセスできないようにするテスト。
「継続的な告知」や「Blackout Test」を行い周知徹底を行っていた。
5.4.2 あらかじめ提供終了時の仕様を盛り込んでおく
API のドキュメントに提供終了後の仕様を記載する。以下は一例。
- 公開終了後はステータスコード 410(Gone) を返す
- エラーメッセージとして API が公開終了していること、新しい API を利用すること等を記載する
自社のモバイルアプリ向け API の場合はアプリ側にも提供終了後の仕様を追加しておく。
(強制アップデート等)
5.4.3 利用規約にサポート期限を明記する
利用規約に古いバージョンをどのくらいの期間サポートをするのかという最低限の期間を定めておく。
→サービスの「保障」と「提供範囲の明確化」を行う
5.5 オーケストレーション層
LSUDs 向けの API では、なるべく汎用性のある設計にする必要がある。一方 SSKDs 向けでは利用者のユースケースに合わせた設計にすることができるが、そのユースケースがいくつも存在する場合はオーケストレーション層を挟むことで対応できる。
サーバ側の汎用的な API とクライアントの間に Client Adapter Code を実行する層を挟み、様々なデバイスに対応できるようにする。この層はオーケストレーション層と呼ばれる。作成するのはクライアント側のエンジニア。
6 章 堅牢な Web API を作る
6.1 Web API を安全にする
6.1.1 どんなセキュリティの問題があるのか
セキュリティの問題には以下のようなパターンがある。
- サーバとクライアントの間での情報の不正入手
- サーバの脆弱性による情報の不正入手や改ざん
- ブラウザからのアクセスを想定している API における問題
6.2 サーバとクライアントの間での情報の不正入手
Web API は通常のウェブサイトと同様に HTTP という暗号化の仕様を持たないプロトコルでやり取りを行う。そのためクライアントとサーバ間の通信経路における情報の不正入手を防ぐ方法が重要。
6.2.1 HTTPS による HTTP 通信の暗号化
最も簡単でなおかつ効果のある方法は HTTP による通信を暗号化すること。
広く利用されているのが HTTPS(HTTP Secure)という TLS による暗号化。
暗号化されるのは以下の情報。
- URI のパス
- クエリ文字列
- ヘッダ
- ボディ(リクエスト・レスポンス両方)
6.2.2 HTTPS を使えば 100% 安全か
ウェブサーバや暗号化機能を提供するライブラリにバグがある可能性があるため、100% 安全であるとは言えない。またクライアント側での処理に問題ある場合も安全性を担保できない。
サーバが送ってきた SSL 証明書を検証しない場合、クライアントとサーバの通信経路の間に入り込んで中継を行い、情報を盗みだすことができてしまう。
サーバ側で対策していてもクライアント側の問題でセッションハイジャックや盗聴が発生する可能性がある。