アンサンブル学習とランダムフォレスト
アンサンブルメソッドは予測器相互の独立性が高いほど性能が高くなる →誤りの犯し方が予測器毎にばらばらになるため
投票方法
ハード
各予測器の予測ラベルを集計、最も投票数が大きいものを予測ラベルとして選出
ソフト
各予測器が推計する確率を平均し、最も高い確率のものを予測ラベルとして選出 →自身の高い投票の重みが増すため、ハードより高い性能が出やすい
サンプリング
バギング
訓練セットから無作為にサブセットをサンプリングする際に、重複ありでサンプリングを行う つまり同一のサブセットに同じ訓練インスタンスが複数含まれる可能性を許す
ペースティング
訓練セットから無作為にサブセットをサンプリングする際に、重複なしでサンプリングを行う
バギングのほうがサブセットの多様性が若干上回る →各予測器の相関が下がる →よいモデルになりやすい
OOB検証
サンプリングされない訓練インスタンス(各サブセットに含まれていないインスタンス)をOOB(out-of-bag)インスタンスという 訓練に使われないため別個の検証セットを作ることなくOOBで検証できる
ランダムパッチ
サンプリングの際に訓練インスタンスと特徴量の両方をサンプリングすること
ランダムサブスペース
サンプリングの際に訓練インスタンスはすべて使い、特徴量のみサンプリングすること
ブースティング
逐次的なテクニック→並列化できないためスケーラビリティに欠ける
アダブースト(AdaBoost)
前の予測器が過少適合した訓練インスタンス(誤分類した)をもとに新しい予測器を修正する。 1. ベース分類器を訓練し、訓練セットを対象として予測をする 2. 分類に失敗したインスタンスの相対的な重みを上げる 3. 更新された重みを使って第2の分類器を訓練する 以降繰り返し
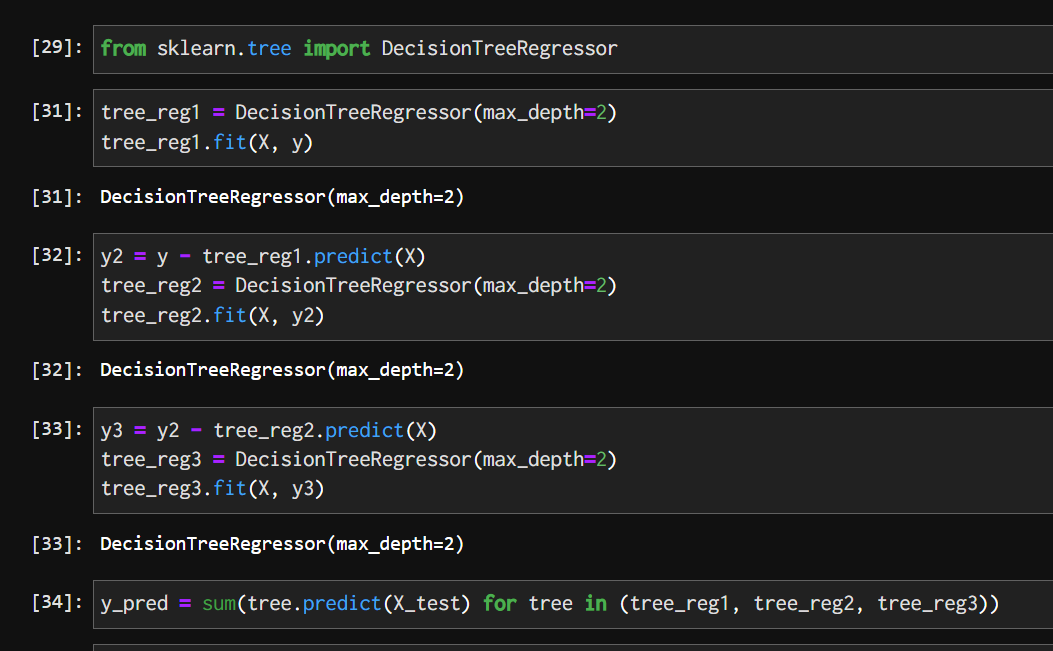
勾配ブースティング(gradient boosting)
アダブーストとは違い、イテレーションごとにインスタンスの重みを調整するのではなく、新予測器を前の予測器の残差に適合させるようにする
スタッキング
他アンサンブルメソッドと同様に複数の予測器を訓練、それらの予測器の出力をもとに結果を出力する最後の予測器(ブレンダ、メタ学習器)を訓練する。